Y_test_dfMLP
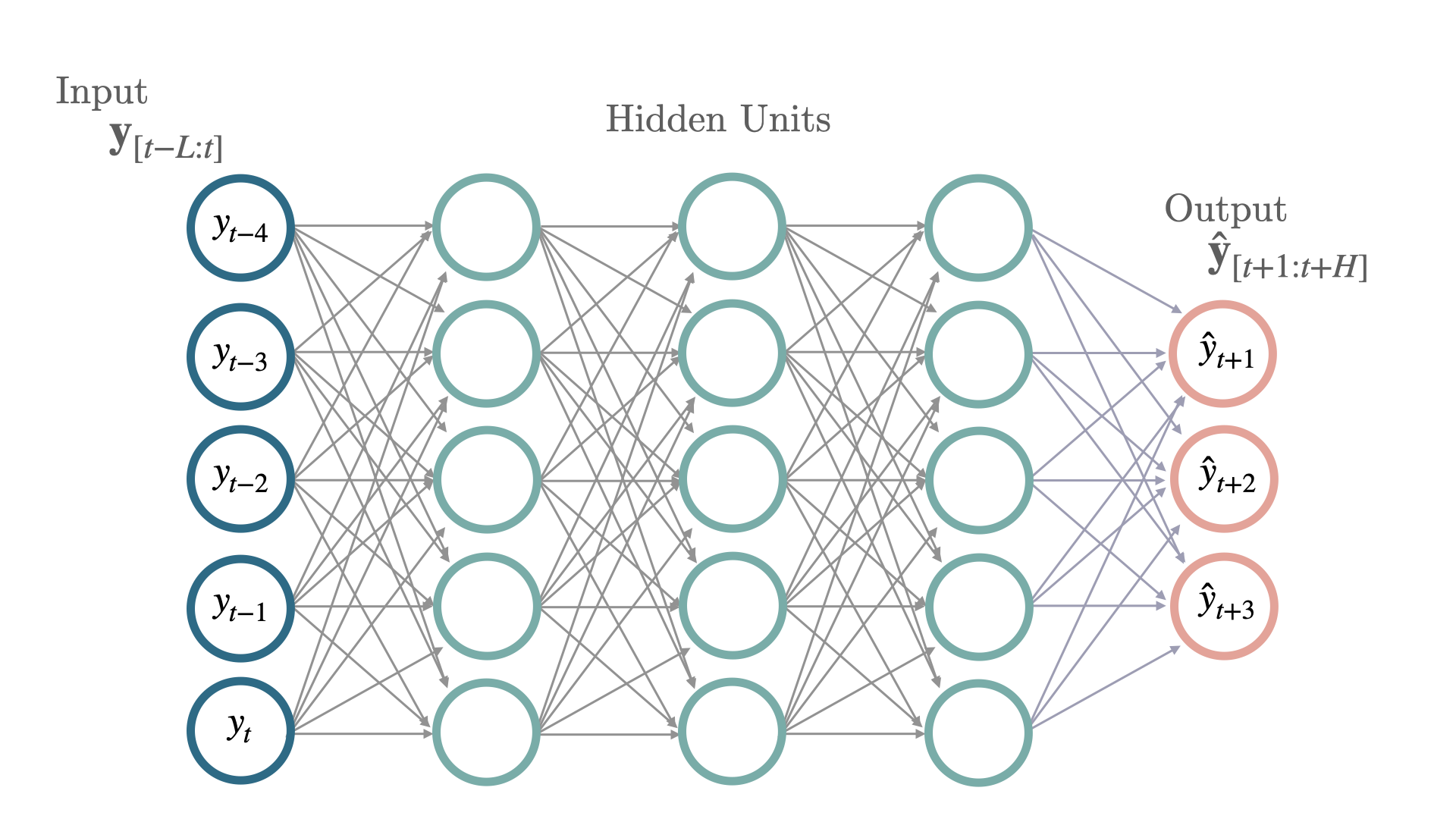
One of the simplest neural architectures are Multi Layer Perceptrons (
References
-Rosenblatt, F. (1958). “The perceptron: A probabilistic model for information storage and organization in the brain.”
-Fukushima, K. (1975). “Cognitron: A self-organizing multilayered neural network.”
-Vinod Nair, Geoffrey E. Hinton (2010). “Rectified Linear Units Improve Restricted Boltzmann Machines”
MLP) composed of stacked Fully Connected Neural Networks trained with backpropagation. Each node in the architecture is capable of modeling non-linear relationships granted by their activation functions. Novel activations like Rectified Linear Units (ReLU) have greatly improved the ability to fit deeper networks overcoming gradient vanishing problems that were associated with Sigmoid and TanH activations. For the forecasting task the last layer is changed to follow a auto-regression problem.References
-Rosenblatt, F. (1958). “The perceptron: A probabilistic model for information storage and organization in the brain.”
-Fukushima, K. (1975). “Cognitron: A self-organizing multilayered neural network.”
-Vinod Nair, Geoffrey E. Hinton (2010). “Rectified Linear Units Improve Restricted Boltzmann Machines”
MLP
MLP (input_size, h, step_size=1, hidden_size=1024, num_layers=2, learning_rate=0.001, loss=<neuralforecast.losses.pytorch.MAE object at 0x7fface2c1240>, random_seed=1)
Hooks to be used in LightningModule.